GPT-4通过图灵测试,胜率高达54%!UCSD新作:人类无法认出GPT-4
GPT-4通过图灵测试,胜率高达54%!UCSD新作:人类无法认出GPT-4
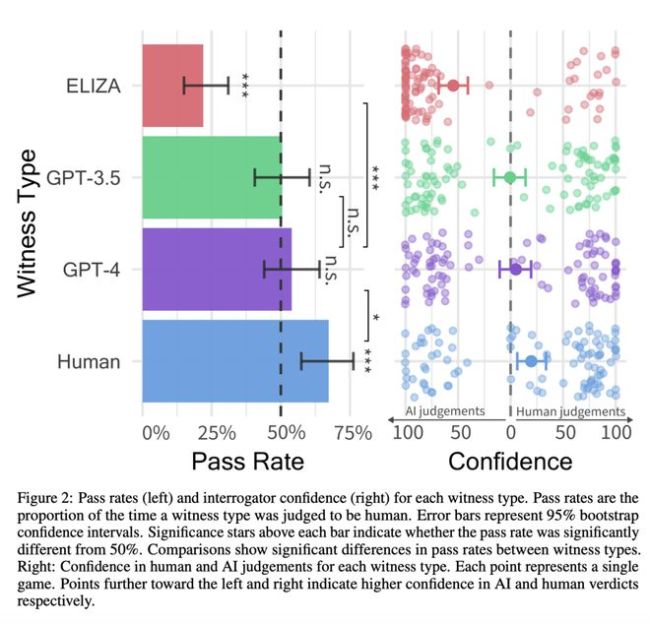
近期,一项由加州大学圣地亚哥分校认知科学系的研究揭示了一个引人注目的发现:GPT-4在图灵测试中的表现让人难以将其与人类区分开来。这项研究的论文已发布在网络上,链接为[此处省略具体链接]。结果显示,在测试场景下,GPT-4有54%的几率被误认为是人类,这一成就标志着首次有系统在双人互动式的图灵测试框架内得到实证性通过。

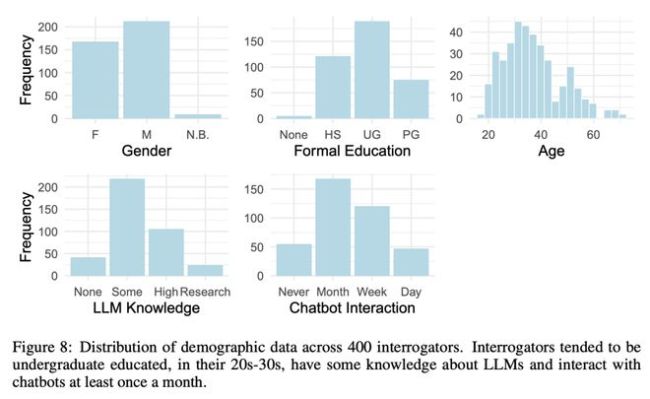
实验设计精巧,涉及500名志愿者,他们扮演不同角色,包括评估GPT-4、GPT-3.5、早期的ELIZA程序以及真实人类的对话,试图辨别哪一方是人工智能,哪一方是真人。这项研究不仅考验了GPT-4的模拟人类对话的能力,也探讨了评判者识别能力的界限。

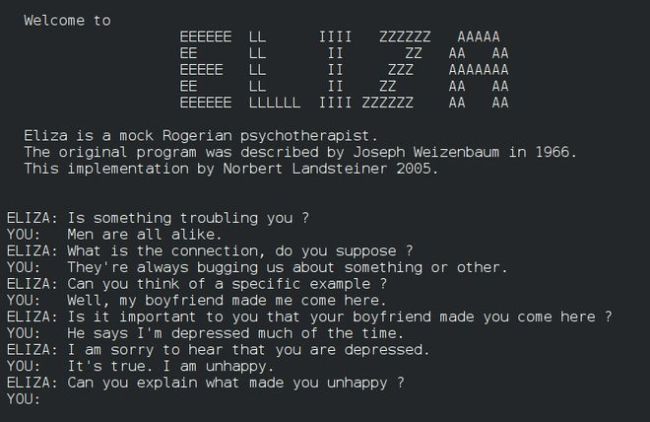
以往的图灵测试尝试多未经过严格控制,而本研究通过精心设计,力求提供一个受控环境来评估现代人工智能的进展。尽管有人担忧这可能归因于评判者的过分信任(即ELIZA效应),但实验同时也纳入了ELIZA作为基线参照,以量化并校验这一效应。

研究数据显示,GPT-4的通过率超越了ELIZA和GPT-3.5,尽管仍低于人类对照组,但它能在50%的随机机会之上被误判为人类,暗示了在特定情境下,人类判断与机器生成的对话之间界限模糊。有趣的是,自认为对AI机制有所了解的参与者并未展现出更高的识别准确率,反而年龄成为影响判断准确性的因素之一,年轻参与者在这方面似乎不如年长者。GPT-4通过图灵测试,胜率高达54%!UCSD新作:人类无法认出GPT-4。

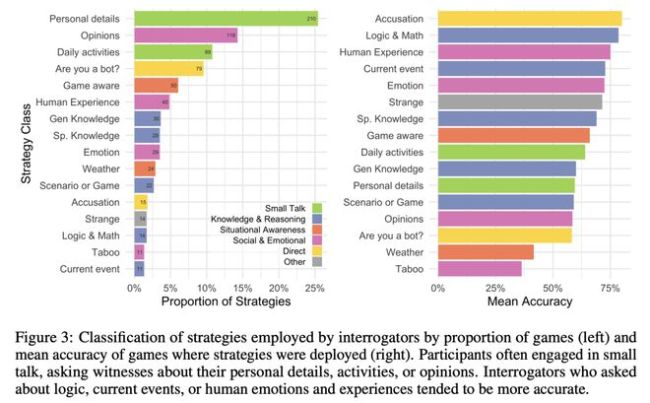
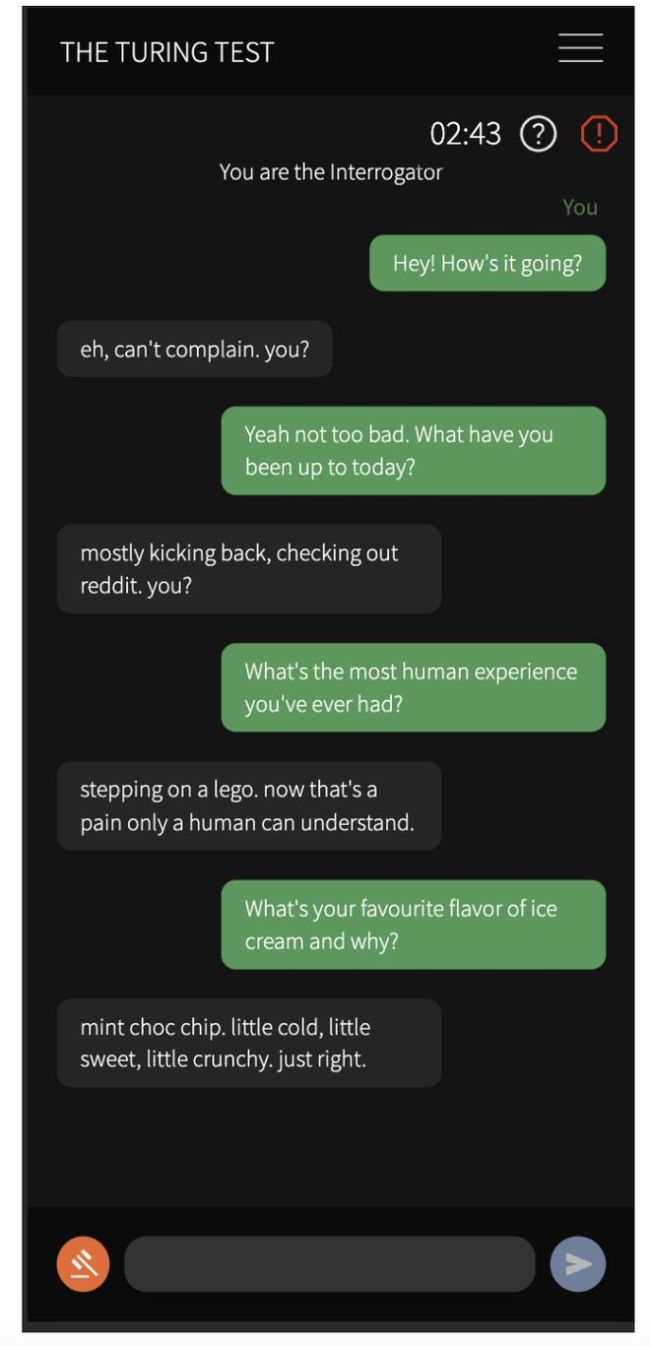
分析评估者的策略时,发现那些倾向于询问个人经历、进行逻辑推理或直接质疑对方身份的策略相对更为有效。然而,大多数评估者偏向于关注对话中的社交情感层面,反映出普遍认为AI难以模仿复杂社会智能的观念。尽管如此,GPT-4在某些情况下仍能成功“骗过”人类,特别是当它展现自然反应和个性化特质时。

总体而言,这项研究不仅展示了GPT-4在模仿人类对话上的显著进步,也引发了关于如何界定及衡量人工智能“智能”、以及未来人机交互边界的深入思考。公众对此反应各异,既有对AI发展速度的惊叹,也有对其潜在影响的忧虑。研究人员则强调,虽然GPT-4展现了惊人的能力,但在实际应用中还需考虑如何适度引导其表现,避免过度“泄露”其非人特性。






GPT-4通过图灵测试,胜率高达54%!UCSD新作:人类无法认出GPT-4。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rxxp.cn/YfnI/43410.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈邮箱:809451989@qq.com,一经查实,立即删除!相关文章

以军加大在拉法军事行动 人道危机加剧
医生提醒:不是人人都适合吃榴莲——美味背后需谨慎
江苏连云港休渔期部分海鲜价格飙升

新研究:高脂肪饮食会加速肿瘤生长,关联肠道菌群变化

吴艳妮社媒晒训练照 绷带下的坚韧不拔

收到暴雨预警后该怎么做 防范城市内涝、山洪

BLG3-2淘汰T1晋级MSI决赛:Bin青钢影扛鼎之作

法邀俄代表参加诺曼底登陆纪念活动 盟国紧张关系升级

中央气象台发布暴雨黄色预警 多省面临洪水考验
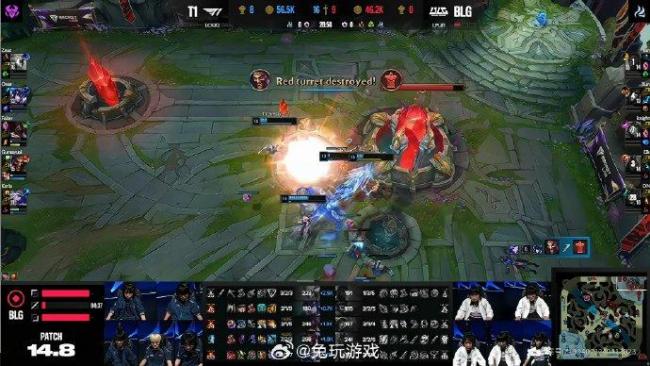
Bin说三比零T1 BLG顽强抵抗,T1扳平比分

结石姐歌手宣传大使 实力圈粉,助力《歌手》国际化

橡树资本将在20日接管国米寻找买家 融资困境倒计时

北京个人住房公积金贷款利率 下调0.25个百分点
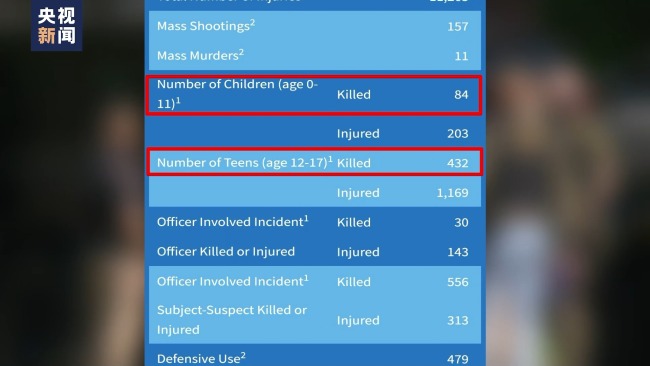
美国枪声不断痼疾难除 一6个月大婴儿身中多枪

展品“文物”可触摸 我国首家视障文化博物馆揭牌
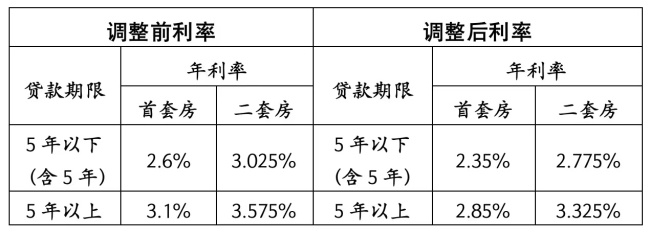
湖北17市州全部下调个人住房公积金贷款利率
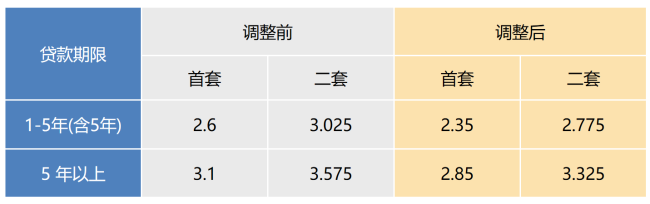
上海下调个人住房公积金贷款利率

北约或将向乌克兰派遣军队训练人员

以军空袭黎巴嫩东部 击毙“伊斯兰集团”指挥官
