我国首次数据资源全面体检 揭示数据生产与利用鸿沟
在第七届数字中国建设峰会上,一项重要成果亮相——《全国数据资源调查报告(2023年)》正式面世,标志着我国首次完成了对数据资源的全面审视。报告揭示,我国已基本确立了数据生产的规模优势,2023年的全国数据生产总量跃升至32.85泽字节(ZB),这一数字相当于超千万个中国国家图书馆数字馆藏的总和,较前一年增长了22.44%。特别是与智能网联汽车出行和工业机器人制造相关的数据,分别以49%和20%的增速迅猛增加,预示着今年数据生产增长率有望突破25%。

国家工业信息安全发展研究中心蒋艳主任指出,5G、AI技术的突飞猛进正推动内容创作、视听娱乐等民生消费领域的新业态蓬勃兴起,这些非结构化数据极大地丰富了我国数据资源的总量。

然而,报告也揭示了一个全球共通的现象:尽管数据生产量庞大,但仅2.9%的数据被保存下来,且存储数据中约有四成在一年内未曾被访问或再利用,凸显了数据生命周期短暂及开发利用效率待提升的问题。

北京交通大学张向宏教授比喻称,未被有效利用的数据如同易腐的水果,迅速丧失其价值,这从侧面反映了我国在数据资源深度开发方面的潜力空间。

报告还关注了算力领域的发展,作为人工智能的关键驱动力,我国算力规模正快速扩张。截至2023年底,全国2200多个算力中心的综合算力达到230百亿亿次浮点计算每秒(EFLOPS),足以为万辆新车模拟上万次碰撞测试于一分钟内完成,年增长率约为30%。其中,智能算力占比升至30%左右,这主要得益于各类大模型的快速发展,特别是在金融、医疗、政务等关键领域,对智能大模型和相应算力的需求日益增强。

区域分布上,京津冀、长三角、珠三角地区的算力规模约占总数的六成,东部分区域的数据使用效率优于西部。
公共数据开放方面,2023年我国公共数据开放量实现16%的增长,省级政府数据开放提速明显,多地开始探索“公共数据授权运营”模式,通过授权企业转化公共数据为产品服务社会,有效拓宽了公共数据的应用场景与获取渠道。尽管如此,数据供需矛盾依然突出,尤其是在消费民生领域,需求方数量是供给方的2.4倍。
蒋艳主任表示,随着数据技术的演进、制度的完善及产业的壮大,数据开发利用水平将逐步提升,供需不平衡问题可望得到缓解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rxxp.cn/FqZi/48385.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈邮箱:809451989@qq.com,一经查实,立即删除!相关文章

赵丽颖《在人间》杀青了 雨夜独行展孤单美,少女心满满惹人爱

35岁医生高血压跑步4个月恢复正常 运动战胜疾病

现场实拍!中国海警编队位台岛以东海域执法演练 强化应急处突能力

汪苏泷 走又走不了赢又赢不了 歌手2024中的坚韧身影

莱希坠机遇难事件 普京最新披露 俄制直升机安全无恙

王楚钦说能赢下来比较侥幸 队友神勇挽救劣势

日本多款功能性标示食品存异常 安全警报再响

跟“电”有关的都涨了,“电茅”又新高,什么情况?新热点蓄势待发

中方机器狗亮相中柬“金龙-2024”联演

AG狼队包揽最佳一二阵 重庆狼队成最大赢家

乌军讲述哈尔科夫前线真实现状 战火中的坚壁清野

张凌赫能不能不要舔嘴唇了 病娇反派霸总新期待

邱彪:阿不都总决赛压力过大导致发挥失常,1个月他体重减了11公斤 新疆男篮败北反思
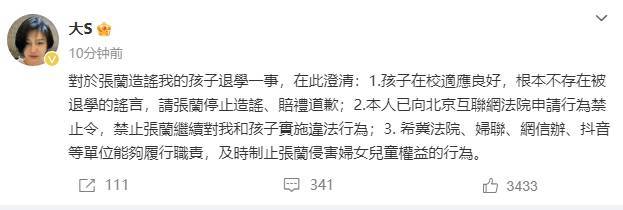
大S发文否认儿子退学:孩子在校适应良好,张兰被要求赔礼道歉

东部战区台岛周边演习彰显三大能力 联合作战新高度

乌克兰65 岁男子谋求加入第 3 独立突击旅:让逃避征兵者无地自容

逆水寒手游致歉 紧急修改游戏内争议内容

泰国公布对阵国足27人名单:8名“新人”入围,黄政宇成焦点
曝布朗尼拒绝签约双向合同 里奇-保罗确认